
みなさん、こんにちは。サニービュー事業部の小寺です。
今日はデータパーティショニングの設計について、お伝えします!
https://aws.amazon.com/jp/builders-flash/202110/saas-data-partitioning/
データパーティショニングとは
データ件数が数百万件に達するようなテーブルを例に考えてみます。膨大なデータ量のテーブルから大量のデータを削除する場合、長い時間が必要となります。削除実行時は、データだけではなくインデックスの削除なども行われ、さらにトランザクションログへの書き込み、排他ロックの発生などによって時間がかかってしまいます。また、データ量の多さからバックアップやインデックスの再構築など、メンテナンスにも多くの時間を要することになります。
その課題を解決するのが「パーティショニング」です。パーティショニングは、データベースにおけるテーブル内のデータを分割して保持する機能です。
データを分割することで性能や運用性が向上します。特に、巨大なテーブルを保持している場合は、テーブル・パーティショニングは有効な手段のひとつです。
ここでは、個別のテーブル・パーティショニングの手法というよりは、データストアとしてどのように性能が出せるか?について、コストやその他の要件に基づき全体を整理していければと思います。
では、データストアはどのように設計すれば良いのでしょうか。
次に、必要なビジネス上の要件に基づいて考えてみます。
パーティショニングを活用するためのビジネス上のポイント
ビジネス要件を整理するにあたって、考慮するべき点は色々あると思います。
完全な回答があるわけではないので、網羅的に考える必要があると思います。
「コンプライアンス」、「パフォーマンス」、「コスト」の 3 点に着目されていました。
簡単に整理してみたいと思います。
・コンプライアンス
データのレジデンシーに関する要件です。レジデンシーってお聞きになったことはありますか。
データレジデンシーは、ユーザーデータを保存する地理的な場所を指します。ユーザーの個人データは、さまざまな理由から、ユーザーの個人データを地域ごとに保存する必要があります。例えば、地域固有の個人情報保護法や規制に遵守するためです。
国内 or 海外、オンプレミス or クラウド、専用ハードウェア or 共有ハードウェアなど、いくつか観点があるかと思います。オンプレミスと一言で言っても、自社のサーバールームなのか、共有 DC のコロケーションなのか、そういった違いも場合によっては重要かもしれません。
・パフォーマンス
基盤となるインフラストラクチャを共有するプールモデルでは、しばしばノイジーネイバーと呼ばれる問題が発生します。クラウドサービスでのずうずうしい「うるさい隣人(ノイジーネイバー)」問題とは、リソースを占有して他のワークロードのパフォーマンスを阻害するワークロードのことです。
システムリソースの大半がそのテナントの処理に消費され、他のユーザーのレスポンスに影響が出てしまうようなことが起こりえます。データベースでも同じ問題が発生する可能性があるので、データ量やクエリパターンを考慮しておく必要があります。
・コスト
そもそもマルチテナントを採用するのは、コスト削減ができるからです。
具体的には、リソースを集約することによるサーバーコストの節約、単一の共有環境を中央管理することによる運用効率の最適化などを図ることができます
ただ、共有環境を使う上では、コンプライアンスやパフォーマンスとのトレードオフになります。
データストアの整理
次にデータストアについて整理してみましょう。
システムで使うデータストアは一つに限定する必要はないです。AWSでは、様々な種類のデータベース / ストレージサービスを利用することができます。
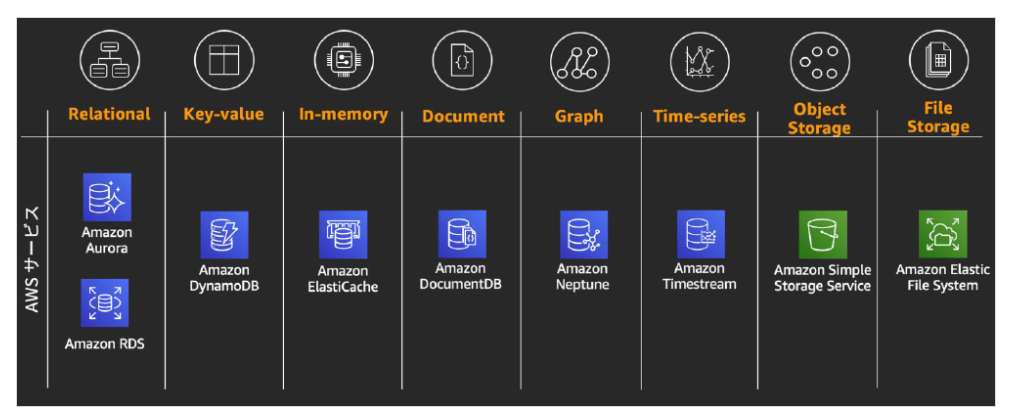
(例)
・Amazon Relational Database Service (Amazon RDS) :トランザクション管理が必要なリレーショナルDB
・Amazon DynamoDB:高スループット・低レイテンシが求められる
・mazon Simple Storage Service (Amazon S3) :画像コンテンツやバックアップ
データベースの設計パターン
パーティショニングの設計について、要件に基づいてパターンが多くあります。まずはリレーショナルデータベースにおける考え方を見ていきます。
例としてデータベースエンジンとして PostgreSQL を、AWS のサービスとして Amazon RDS を利用するケースを検討してみます。この場合、取り得るパーティショニングのパターンは大きく 4 つあります。
1)テナントごとにそれぞれ RDS インスタンスを用意し、それぞれのインスタンス内にテナント固有のデータベースを作成する (サイロモデル)
2)共有 RDS インスタンスを用意し、その中にテナント固有のデータベースをそれぞれ作成する (インスタンス共有プールモデル)
3)共有 RDS インスタンスおよび共有データベースを用意し、その中にテナント固有のスキーマをそれぞれ作成する (データベース共有プールモデル)
4)RDS インスタンス、データベース、スキーマ全てを複数テナントで共有する (スキーマ共有プールモデル)
まとめ
データベースエンジンやデータストアの種類によって、アーキテクチャを複数利用することが推奨。
ビジネス上の要件は、コンプライアンス、パフォーマンス、コストの3つに分けて考えることが可能。
SunnyCloudでは、直接契約よりもAWSを5%割引料金で利用できる、初期費用・手数料無料のAWSリセール(請求代行)サービスを提供しています。 無料相談会も受付中です!⇒こちら





