
こんばんは。ご無沙汰しています。小寺です。
梅雨明けかと晴天の日もあれば、急な雨に慌てて洗濯物を取り込む日々です。
今日はAmazon Redshiftのサービスプログラムデリバリー認定を昨日取得いたしました。
そんなこんなで、Amazon Redshiftについて、どのようなサービスなのか?を解説いたします。
Amazon Redshiftとは
Amazon Redshiftとは、AWS上で提供されているスケーラブルで高速、費用対効果が高くペタバイト規模のデータウェアハウスサービスです。
費用対効果の部分では、支払い方法の最適化も行うことができ、 1時間あたり0.25 USDから開始でき、1 年間、1テラバイトあたり1,000 USDまでスケールアウトが可能です。
あらゆるデータを構造化して蓄積し、高速に分析処理できることができます。
データウェアハウス(DWH)というのは、さまざまなデータの元となる場所からデータを収集・統合・蓄積し、分析のため保管しておくシステムです。
データウェアハウスって良く聞くけど、なかなかご説明は難しいですよね。
データウェアハウスの利点は次のとおりです。
・情報に基づく意思決定
https://aws.amazon.com/jp/data-warehouse/
・多数のソースから統合されたデータ
・履歴データの分析
・データの品質、一貫性、正確性を維持
・分析処理をトランザクションデータベースから分離し、両システムのパフォーマンスを向上
RDBMSと比較すると、継続的な書き込みや更新には向いていないので、一括でデータを格納して、取り出すような処理がおすすめです。
Amazon Redshiftのユースケース
どんなときに使われるサービスなのでしょうか。ユースケースとしては以下が考えられます。
・経営ダッシュボード
・小売り・流通業のダッシュボード
・ETL/パッチ
・機械学習の前処理
Amazon Redshiftの特長
・AWS サービスの統合
AWS他サービスや特に機械学習サービスとのネイティブな統合により、分析の処理も簡単に行えます。
例えば、AWS Lake Formationを使うことで安全なデータレイクを数日で簡単にセットアップできるサービスです。AWS Glueと連携すれば、Amazon Redshift にデータを抽出、変換、ロード (ETL) することができます。
また例として、Amazon Kinesis Data Firehose を使用すると、最も簡単な方法で Amazon Redshift にストリーミングデータをキャプチャ、変換、ロードでき、ほぼリアルタイムで分析を行えます。Amazon EMR を使用すると、Hadoop/Spark を使用してデータを処理し、出力を Amazon Redshift にロードしてビジネスインテリジェンスや分析を行えます。Amazon QuickSight は、セッション単位の料金で利用できる初の BI サービスで、Redshift データに関するレポートやダッシュボードを作成することや、可視化することができます。Amazon Redshift を使用してデータを準備し、Amazon SageMaker で機械学習 (ML) ワークロードを実行できます。
AWS Schema Conversion Tool と AWS Database Migration Service (DMS) を使用して、他のDBからAmazon Redshift への移行が簡単にできます。
・横串検索(フェデレーテッドクエリ)
Amazon Redshiftで横串検索機能(フェデレーテッドクエリ)を使用すれば、リレーショナルデータベースにアクセスできます。
1 つ以上の Amazon Relational Database Service (RDS)、Aurora PostgreSQL、RDS MySQL、Aurora MySQL データベースへアクセスし、直接クエリできる機能です。
データ本体は外部データベースに置いたまま、外部データベースのテーブルにクエリを発行して分析に利用できます。
・Amazon S3 からの自動コピー
継続的なデータ取り込みのためのシンプルなデータパイプラインを簡単に作成、維持できるようになる Amazon Redshift auto-copy from S3機能がサポートされています。
指定したS3上に到着したファイルをデータ ウェアハウスに自動的にロードします。ファイルは、CSV、JSON、Parquet、Avroなど、RedshiftのCOPYコマンドでサポートされている任意の形式を使用できます。
Amazon Redshiftのベストプラクティス
・テーブル設計編
テーブル設計が全ての要になるといっても過言ではないです。全体的なパフォーマンスに対してのボトルネックになりやすい部分でもあります。
クエリパフォーマンスを最適化するためにも以下を実施しましょう。
まずは、ソートキーがあげられます。テーブルのデータを特定の列(カラム)でソートする基準になるキーです。
Amazon Redshift クエリオプティマイザは、最適なクエリプランを決定する際にソート順を使うからです。
次に、VACUUMを実行しないで済むように設計する例えば、VACUUM不要なスキーマにするよう、日付をソートキーとしたINSERTのみのファクトテーブルにし、更新や削除を極力なくすことも重要です。
自動圧縮を利用することも有効です。テーブル作成時に最適な圧縮エンコードを選んでおけば、ストレージのスペースが節約され、ストレージからロードするデータ量が小さくなり、ディスクI/Oの量が減少するため
1COPYで複数ファイルを並列ロードし、ロード操作の一部として自動的に空のテーブルに圧縮エンコードを適用します。
・クエリ設計編
クエリパフォーマンスを最大化するには、必要なベストプラクティスについてお伝えします。前提としてはテーブル設計編にしたがったもので作ってもらう必要ありです。
同じテーブルから複数回SELECTをするのではなく、CASE 条件式 を使用して複雑な集計を実行します。
・データロード編
大量のデータセットのロードには時間がかかり、大量にリソース消費し、データのロード方法によっては、クエリパフォーマンスにも影響を与える可能性があります。
ファイル分割、ファイル圧縮を実施した上での実行が望ましいです。
サニークラウドが提供するデータ基盤(Amazon Redshift)導入サービス
データ基盤ソリューションは、クラウドの特性を活かし、低コストで拡張性の高いデータレイクの構築、フルマネージドのデータウェアハウス構築、データレイクとデータウェアハウスの連携を実現し、あらゆるお客様のデジタルトランスフォーメーション推進をご支援しております。
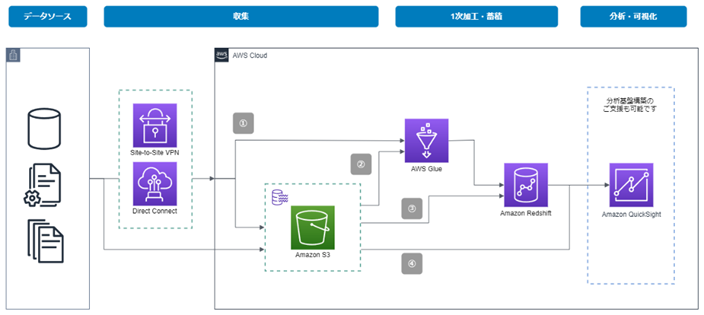
①AWS Glue (ETLサービス)を用いてソースDBと直接接続し、DWHにデータ連携を行う
②①の類似パターンとして、データレイク(Amazon S3)を介してのデータ連携も可能
③データレイク(Amazon S3)に保管したデータをAmazon Redshiftの機能(Amazon Redshift spectrum)を用いて直接ロードすることも可能
④分析基盤としてAmazon QuickSightを用いる場合には、DWHとの接続のみならず、S3直接参照等も可能
お問い合わせはこちらから。





