
こんばんは、小寺です。
OpenSearch Serverlessの時系列コレクションのサイズが10TBに拡張されました。
https://aws.amazon.com/about-aws/whats-new/2024/03/amazon-opensearch-serverless-time-series-workloads-10tb/
OpenSearch Serverlessを振り返る
そもそもOpenSearchはどんなときに利用されるの?
・ユースケースその①:全文検索
半構造化データ、非構造化データの様々な観点を通じて、最適な製品、サービス、ドキュメント、回答を簡単に見つける。
・ユースケースその②:ログ分析
AWSサービスのログから問題を特定、診断、修正する。
製品の遅延と安定性を改善する。
大量のログデータからインサイトを得る。
OpenSearch Serverlessになって変わったことまとめ
クラスターのプロビジョニング、設定、チューニングなどの運用の負荷がなくなるメリットがあります。
データ管理や基盤について、考慮せずに大量データの分析や検索ができるようになります。
仕組みとしては、従来のOpenSearchクラスターには、インデックス作成と検索の両方を実行できるインスタンスセットがありました。データが増えれば増えるほど、大量データを扱うパフォーマンスが出せるインスタンスが必要です。
一方でOpenSearch Serverlessは、軽量化されたため、上記の大量データをさばく仕組みを新たにもっているといえます。
例えば、データ取り込みと検索を分けて機能を実現しています。
インデックス作成 (取り込み) コンポーネントと検索 (クエリ) コンポーネントを分離しています。

OpenSearch データインジェスト、検索、クエリのサーバーレスコンピューティング性能は「OCU」(OpenSearch Computing Unit)で測定されます。
コレクション
OpenSearch Serverless は、次の 3 つの主要なコレクションタイプをサポートしています。
コレクション名、コレクションタイプ、および暗号化設定は、作成後に変更できないので要注意です!
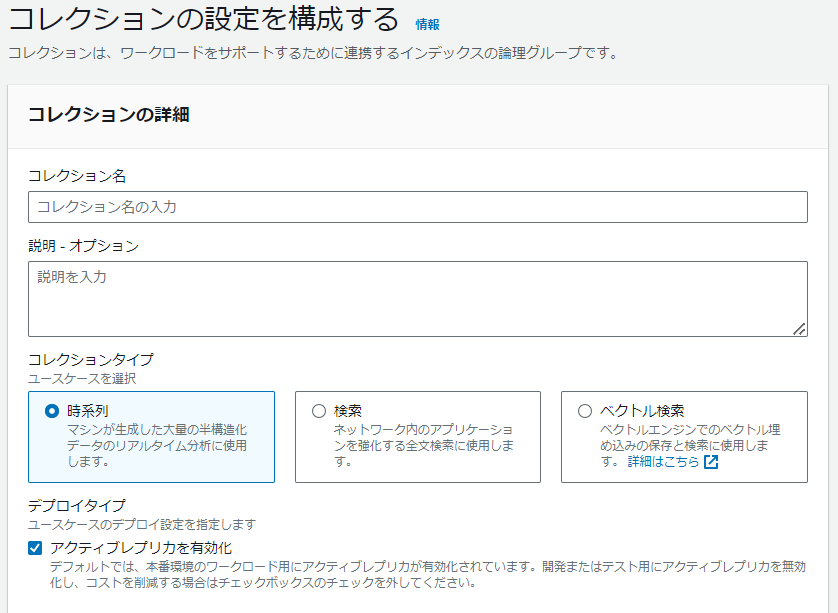
[時系列]
運用、セキュリティ、ユーザー行動、およびビジネスに関するインサイトを得るために、マシン生成による大量の半構造化されたデータをリアルタイムで分析することに重点を置いたログ分析セグメント。
[検索]
社内ネットワーク内のアプリケーション (コンテンツ管理システム、法的文書) や、e コマースウェブサイト検索やコンテンツ検索などのインターネット向けアプリケーション向けの全文検索。
[ベクトル検索]
ベクトルデータ管理を簡素化し、機械学習 (ML) によって拡張された検索エクスペリエンスと、チャットボット、パーソナルアシスタント、不正検出などの生成 AI アプリケーションを強化する、ベクトル埋め込みのセマンティック検索。
アップデート内容
Amazon OpenSearch Serverless が、コレクション内に1 つ以上のインデックスを時系列データのスキャンと検索が10TBまでできるようになりました。コレクションタイプの時系列のデータはアップデート前までは6TBだったので、4TBの容量アップですね。 その他の検索、コレクションごとのインデックスサイズ は1TBのままになっています。
さらに、OpenSearch Serverless はインデックス作成と検索にそれぞれ 200 OCU をサポートするようになりました。AZ の停止やインフラストラクチャ障害に対する冗長性を含め、以前の制限の 100 から2倍になっています。
検索とインデックス作成の最大 OCU のクォータ設定もできるようですね。 CloudWatch メトリクスから実際に利用されている OCUの使用状況をモニタリングすると、ワークロードのリソース消費を今よりもっとちゃんと把握できるようになりますね。
まとめ
実は調べてみると、Document Histryは2023年11月になっていました。知らないうちのアップデート面白いなー。 最大 OCU はインデックス作成と検索でそれぞれ設定がされているので、実際のパフォーマンスを測定して、チューニングできるようになれば、便利だと思いました。





