
みなさん、こんにちは。
Amazon EC2 にはインスタンスが「どのような状態であるか」をモニタリングする機能があります。一般的によく使われるのが、「ステータスチェック」のモニタリングです。
この「ステータスチェック」では、何かインスタンスに問題があった際に、まずはステータスチェックを確認し、問題切り分けをすることが可能です。
今回のコラムでは、Amazon EC2 の「ステータスチェック」について、何か問題があった時に、素早いアクションを行うための「Amazon CloudWath のアラーム設定」について、一部抜粋してご説明いたします。
■ Amazon EC2 のステータスチェックとは
Amazon EC2 におけるステータスのモニタリングでは、OS またはミドルウェアからアプリケーション、AWS 基盤側の問題などが検出されたかどうかをすばやく判断することが可能です。
ステータスチェックは 1 分ごとに実行されることにより、成功または失敗のステータスを更新します。インスタンス全体のステータスチェックが成功すると、”OK” となり、インスタンス全体のステータスチェックが失敗すると、”impaired” を AWS マネジメントコンソールなどから確認することが可能です。また、ステータスチェックに失敗した場合は、ステータスチェックの対応する Amazon CloudWath メトリクスのデータポイントが “0” から “1” に変化します。
ステータスチェックには、大きく 2 つのタイプがあり、「インスタンスステータスチェック」および「システムステータスチェック」の種類があります。
■ インスタンスステータスのチェックとは
インスタンスステータスチェックは、インスタンスのソフトウェアとネットワークの設定をモニタリングします。Amazon EC2 では、NIC (ネットワークインターフェース) に対して、ARP (アドレス解決プロトコル) リクエストを送信することでインスタンスのヘルスチェックを行います。
たとえば、インスタンスステータスチェックの失敗の原因となる問題は、下記の可能性が考えられます。
・Amazon EC2 インスタンスにおける失敗したシステムステータスチェック
・Amazon EC2 インスタンスにおける正しくないネットワーク設定または起動設定
・Amazon EC2 インスタンスにおけるメモリの枯渇
・Amazon EC2 インスタンスにおける破損したファイルシステム
・Amazon EC2 インスタンスにおける互換性のないカーネルなど
インスタンスステータスチェックに失敗した場合のトラブルシューティングは、EC2 Windows であればイベントログやメモリダンプなどを解析する、または OS 上で稼働中のミドルウェアや、その他のソフトウェアのログに対して関連記録が残っていないか確認することが有効です。
インスタンスステータスのチェックに失敗した原因は、OS または、アプリケーションレイヤーの問題の影響を受けた可能性が考えられるため、常時インスタンスのバックアップを取得し、問題ない状態のインスタンスへ復旧する運用がおすすめです。
■ システムステータスのチェックとは
システムステータスチェックは、インスタンスが実行されている AWS システムをモニタリングします。
このチェックでは、インスタンスの根本的な問題 (AWS 側の障害など) が検出されます。システムステータスチェックが失敗した場合、AWS が問題を解決するのを待つか、自分で解決できるかを選択できます。
Amazon EBS ベースのインスタンスの場合は、インスタンスを停止、および起動することで、システムステータスチェックが成功となり、インスタンスが復旧する可能性があります。これはインスタンスの停止、および起動することで、仮想サーバーホストの再選択が期待できるからです。そのため、問題である仮想サーバーホスト上で稼働していたインスタンスは、新しい仮想サーバーホストに移動して稼働することによって、問題が解決する可能性があります。
システムステータスチェックに失敗した際は、まずは、問題切り分けの初手として、インスタンスの停止、および起動を行いましょう。その際、アクションとしての注意点はインスタンスの「再起動」ではなく「停止および起動」であることです。インスタンスの「再起動」の場合は、仮想サーバーホストの再選択は行われないため、システムステータスのチェックは復旧しないため、注意が必要です。
たとえば、システムステータスチェックの失敗の原因となる問題は、下記の可能性が考えられます。
・AWS 側のネットワーク接続の喪失
・AWS 側のシステム電源の喪失
・物理の仮想サーバーホストのソフトウェアの問題
・AWS 側のネットワーク到達可能性に影響する、物理ホスト上のハードウェアの問題
■ Amazon CloudWath メトリクス
Amazon CloudWath メトリクスを使用して、ステータスチェックの結果に紐づいてトリガーする Amazon CloudWath アラームを作成することができます。
Amazon CloudWath メトリクスとは、システムのパフォーマンスに関するデータを指します。
たとえば、Amazon CloudWath メトリクス “StatusCheckFailed_Instance” では、直近 1 分間にインスタンスが “インスタンスステータスチェック” に成功したかどうかをレスポンスします。このメトリクスは 0 が OK。1 が失敗となります。
また、Amazon CloudWath メトリクス “StatusCheckFailed_System” では、直近 1 分間にインスタンスが “システムステータスチェック” に成功したかどうかをレスポンスします。このメトリクスは 0 が OK。1 が失敗となります。
■ Amazon CloudWath アラームについて
Amazon EC2 を運用中にステータスチェックに失敗しても、失敗に気づくことができなければ、サービス停止などに気づかない可能性があり、ビジネスにおける機会損失が生まれることが考えられます。
そんな問題を解決するには、Amazon CloudWatch アラームが有効となります。何か問題があった際でも、Amazon CloudWatch アラームをあらかじめ作成していれば、メールまたは SMS などでアラート通知で早く気づくことが可能です。
Amazon CloudWatch アラームは非常に多機能で、細かい設定が可能です。アラームの状態は下記の 3 点があります。
・OK : メトリクスまたは、メトリクスの数式は、定義したしきい値を下回っている。
・ALARM : メトリクスまたは、メトリクスの数式は、定義したしきい値を超えている。
・INSUFFICIENT_DATA : Amazon CloudWatch アラームが開始直後であるか、Amazon CloudWatch メトリクスが利用できないか、データが不足していてアラームの状態を判定できない。
このアラームの状態を決定する評価方法についての詳細は、下記のドキュメントをご参照ください。
[1] アラームを評価する
■ StatusCheckFailed_System がトリガーされた際の EC2 インスタンスを復旧させるアクションが、非常に有効な件について。
今回は、一例として AWS 側の基盤に障害が発生し、Amazon CloudWatch メトリクス “StatusCheckFailed_System” が発生したときに、Amazon CloudWatch アラームをトリガーすることによって、自動的にインスタンスを復旧させることについてご案内します。
“StatusCheckFailed_System” がトリガーされた場合は、前述でも説明したとおり一般的には AWS 基盤側の問題が発生した場合が多いです。そのため、当該事象が発生した場合には、問題が発生したインスタンスの停止、および起動のアクションを自動で設定しておくことにより、ダウンタイムを極力少なくすることが期待できます。
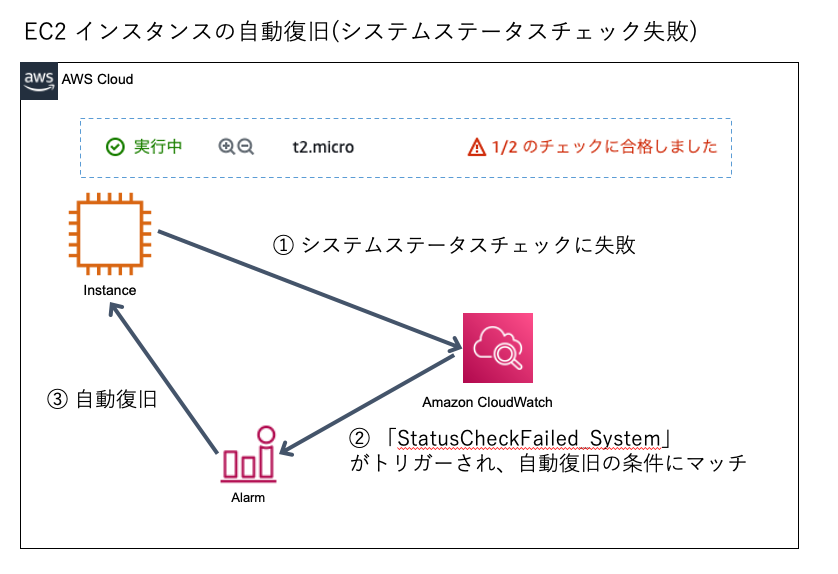
詳細のアラーム作成手順につきましては、下記のドキュメント[2]をご参照ください。
[2] Amazon CloudWatch アラームへの復旧アクションの追加
■ まとめ
いかがでしたでしょうか。
Amazon EC2 を運用する際は、何か問題が発生した際には、まず「ステータスチェック」の確認を行いましょう。とお伝えいたしました。
Amazon EC2 の OS 内部をカスタマイズされるお客様も多いかと存じます。その際には、あらかじめ検証環境にて「インスタンスステータスチェック」を確認しながら、作業しましょう。
なお、「システムステータスチェック」に失敗した際には、トラブルシューシューティングの初手として、インスタンスの停止、および起動を行うことをお試しください。
SunnyCloudでは、AWSビジネスサポートが無料で利用でき、利用料金も割引になるお得なAWSリセール(請求代行)サービスを提供しています。

AWSをご利用いただくには、直接契約するより断然お得。
AWS利用料が5%割引、さらに日本円の請求書による支払いが可能です!




