
みなさん、こんばんは。サニービュー事業部の小寺です。
Amazon Comprehendがファイルの入力をサポートするようになりました。
Amazon Comprehendとは
Amazon Comprehendは、テキストを理解する上で重要な、エンティティ、キーフレーズ、感情などを、機械学習を使用してテキストから洞察を見つける自然言語処理 (NLP) サービスです。
キーフレーズ(会話のポイント)を抽出したり、感情分析を行ったりできるので、グローバルにおける製品レビューの評価等にも活用できます。
・Entities:ドキュメントで識別された、人物、場所、場所などのエンティティのリストを返します。
・キーフレーズ:ドキュメントに表示されるキーフレーズを抽出します。たとえば、フットボールゲームに関するドキュメントは、チーム名、会場名、最終的なスコアを返します。
・PII:住所、銀行口座番号、電話番号など、個人を識別するために使用できる個人データを検出するためにドキュメントを分析します。
・Language:ドキュメントの主要な言語を識別します。100 個の言語を識別できます。
・感情:ドキュメントのワードを分析して感情を決定します。感情は、正、中立、負、混合のいずれかです。
・構文:ドキュメント内の各単語を解析し、その単語の品詞を決めることができます。
アップデート内容
今まではPDF ドキュメント、Microsoft Word ファイル、画像などの半構造化ドキュメントの処理を行うには、光学式文字認識 (OCR) などの前処理技術を活用した複数のAPIの呼び出しが必要でした。
そのため、APIでテキストを抽出してから、NLP 処理を行う必要がありました。
このアップデートによって、APIの呼び出しは1回だけになり、スキャンしたドキュメントまたはデジタルの半構造化ドキュメント (PDF、Microsoft Word ドキュメント、ネイティブフォーマットの画像) と、プレーンテキストのドキュメントの両方を処理できるようになりました。NLPとOCR を組み合わせることによって、前処理のオーバーヘッドをなくすことができ、より簡単に処理ができるようになりました。
試してみる
最初に分析したいファイルをS3にアップロードしておきます。
(1)Amazon Comprehendから「Analysis jobs」を選び「Create Jobs」をクリックします。
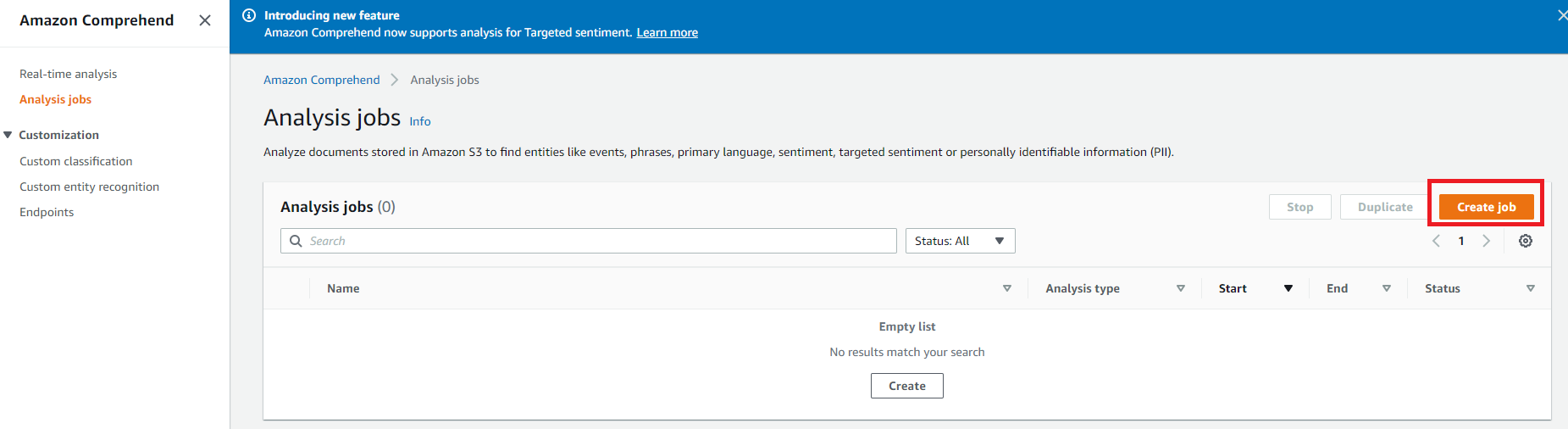
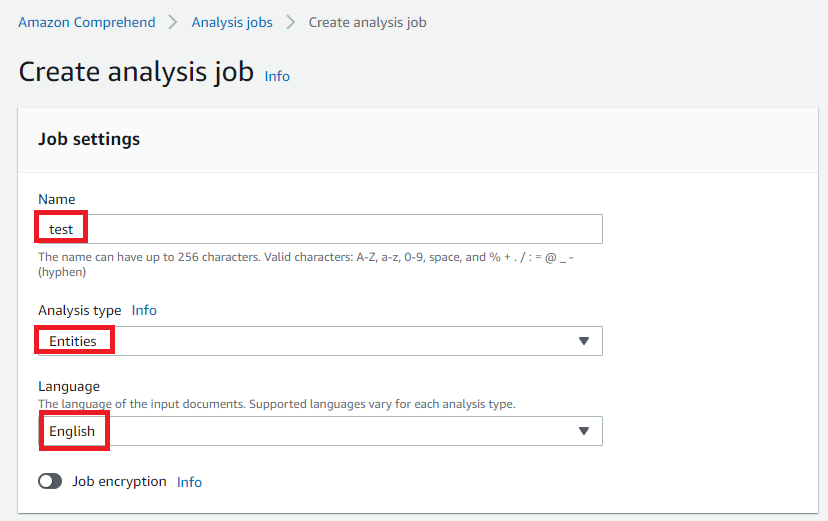
(2)「Create analysis job」画面で、まずJob設定を行います。
ジョブ名はtest、Analysis typeはEntities、LanguageはEnglishを選びました。
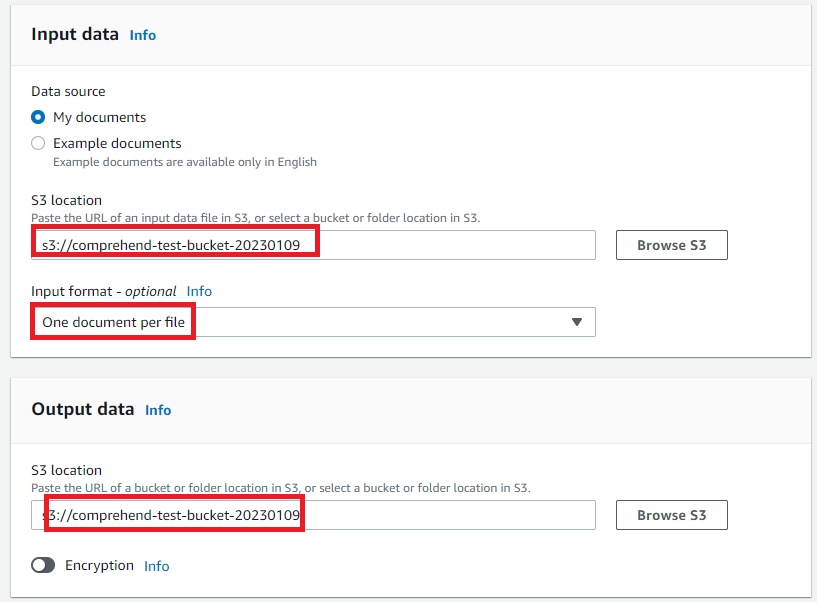
(3)Input Dataはサンプルデータもありましたが、予め準備しておいた画像を分析してみようと、作成しておいたS3バケットを指定しました。
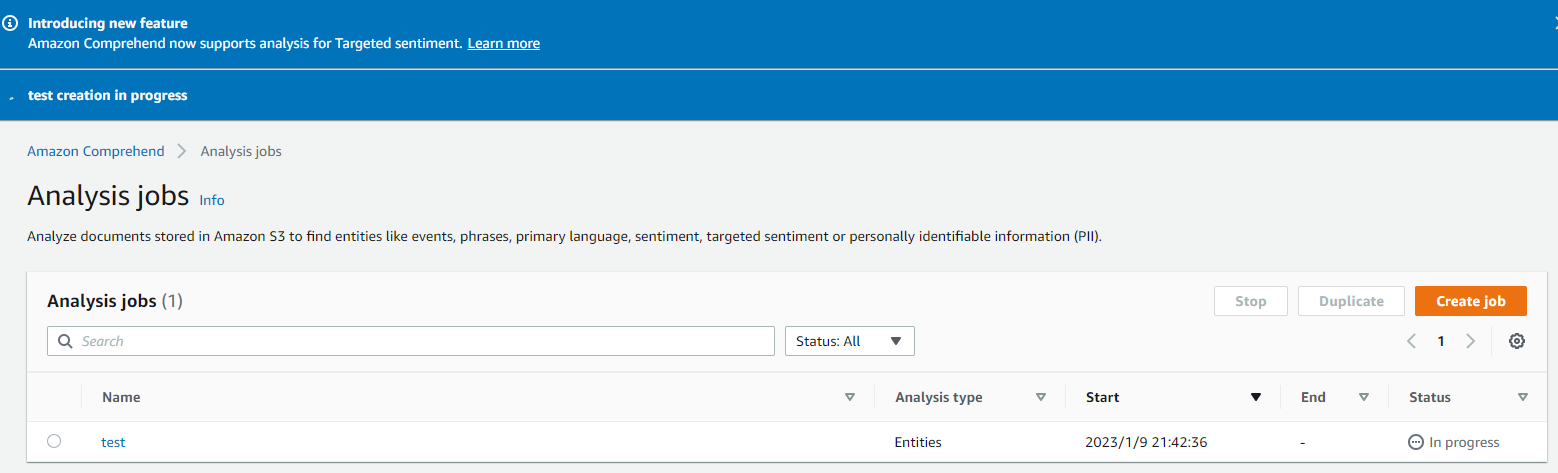
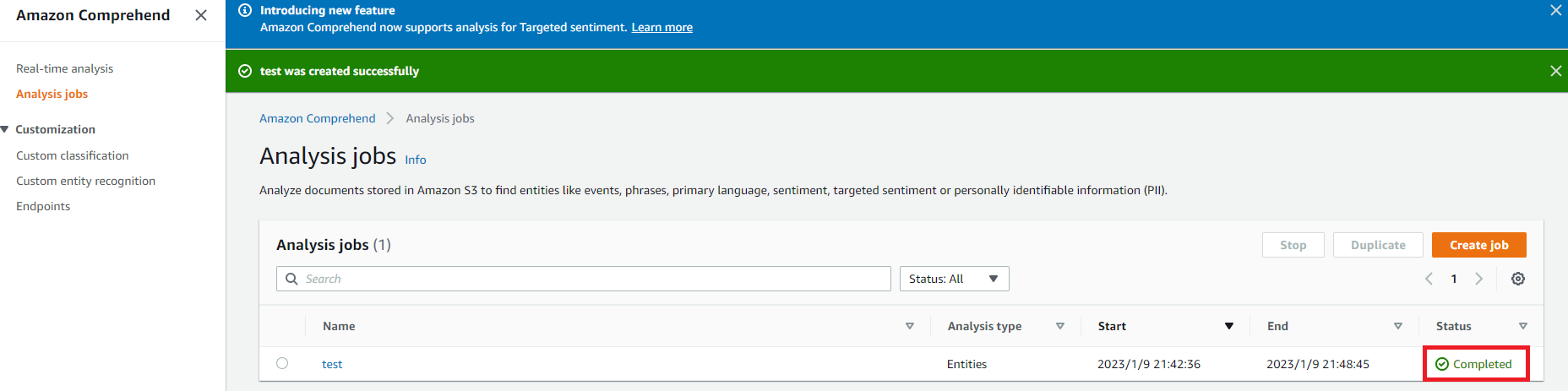
(4)ジョブ実行中の画面になります。
(5)ジョブが完了しました。数分かかりました。
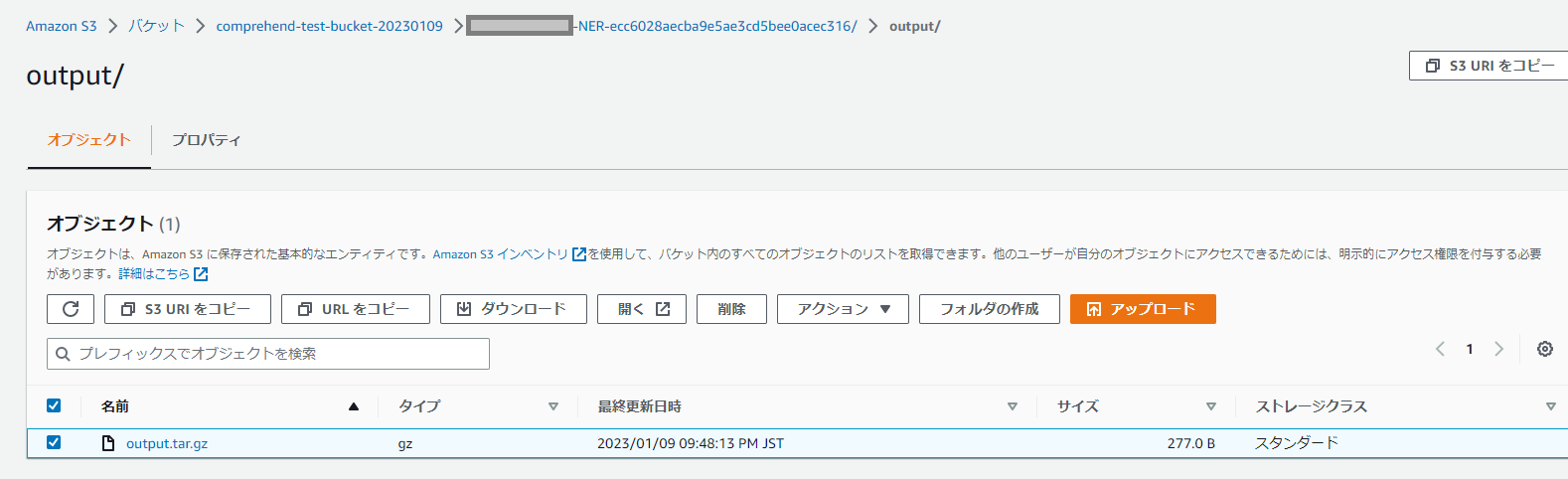
(6)結果については、S3のバケットから確認ができます。
Amazon S3バケット>comprehend-test-bucket-20230109/AWSID-NER-ecc6028aecba9e5ae3cd5bee0acec316/output/
指定しておいたバケットのoutputに「output.tar.gz」ファイルができています。
コンソールだけで処理が完結できるようになりました。ちなみにファイルを開いてみると以下のエラーで画像自体の確認はできませんでした。別のUTF-8形式で別途トライしてみます。
{"Entities": [], "File": ".write_access_check_file.temp"}
{"ErrorCode": "UNSUPPORTED_ENCODING", "ErrorMessage": "Document is not in utf-8 format and all subsequent lines are ignored.", "File": "pic1.png"}
Amazon Cpmprehendの多言語サポート
以下の言語がサポートされています。
・ドイツ語
・英語
・スペイン語
・イタリア語、
・ポルトガル語
・フランス語
・日本語
・韓国語
・ヒンディー語
・アラビア語
・中国語 (簡体字)
・中国語 (繁体字)
その中でも本アップデートで、エンティティ抽出に対応したのは英語、分類に対応したのは英語、ドイツ語、スペイン語、フランス語、イタリア語、ポルトガル語です。
まとめ
いかがでしたでしょうか。前処理なしに、PDFやWord、画像ファイルを解析できるようになって、ますます便利になりましたね。





