
こんばんは、小寺です。
先週のアップデートを振り返ってみようと思います。
https://aws.amazon.com/jp/about-aws/whats-new/2024/04/guardrails-amazon-bedrock-available-safety-privacy-controls/
Guardrails for Amazon Bedrock とは
昨年12月のre:Inventで発表されたサービスですね。 自然言語によるやり取りを行う際に、AI の利用ポリシーに合わせてカスタマイズして有害、危険なコンテンツをブロックする機能です。
「責任あるAI」という言葉をお聞きになったことがある方も多くいるかと思います。もちろん、各モデルには 有害な、危険な、悪意のあるユーザー入力には応答しないような仕組みが提供されています。
しかし、LLMが搭載している有害、危険、悪意のあるという判断基準は一般的なものなので、 各ユースケースに基づいた「機密情報」や「特定業務ナレッジ」のような固有の情報を制御するには不十分な面があります。そのため Guardrails for Amazon Bedrock機能を利用することで、拒否トピックとコンテンツフィルターを定義して、ユーザーとアプリケーション間のやり取りから望ましくない有害なコンテンツを削除したり、マスクすることができます。
試してみる
(1)セーフガードより「ガードレール」をクリックします。
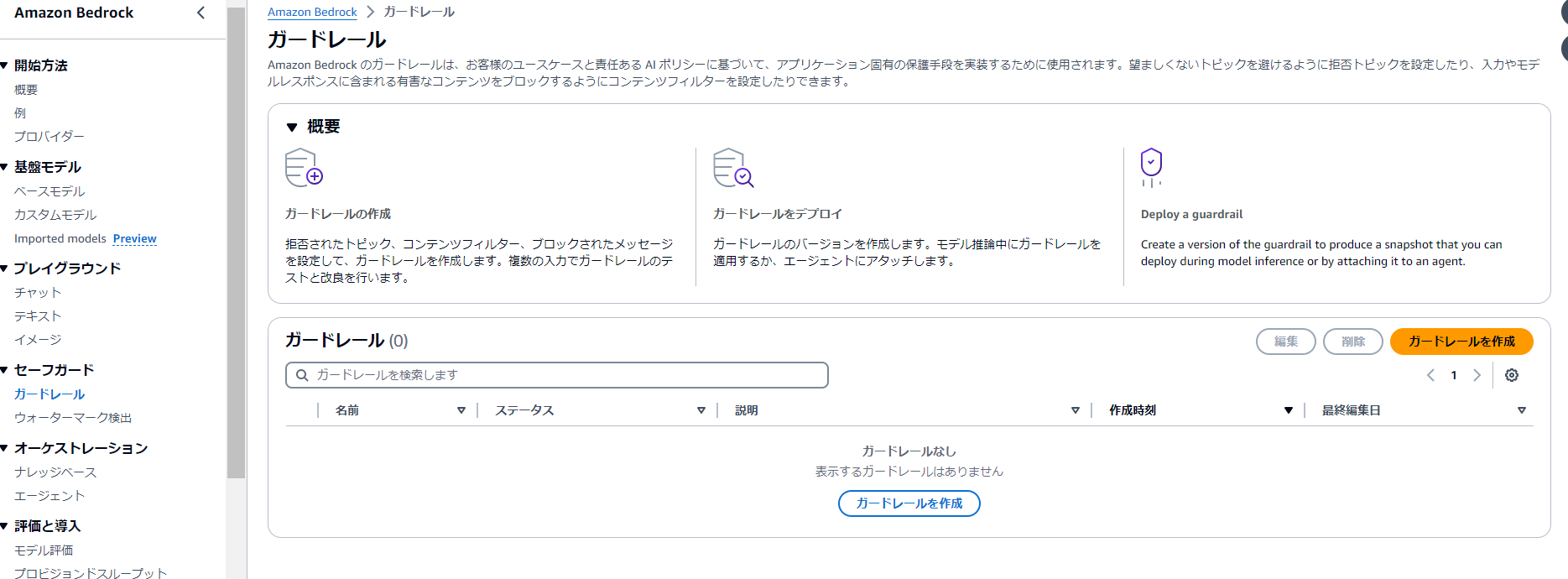
(2)ガードレールは以下の4つの要素から構成されています。
- コンテンツフィルター
- 拒否されたトピック
- ワードフィルター
- 機密情報フィルター
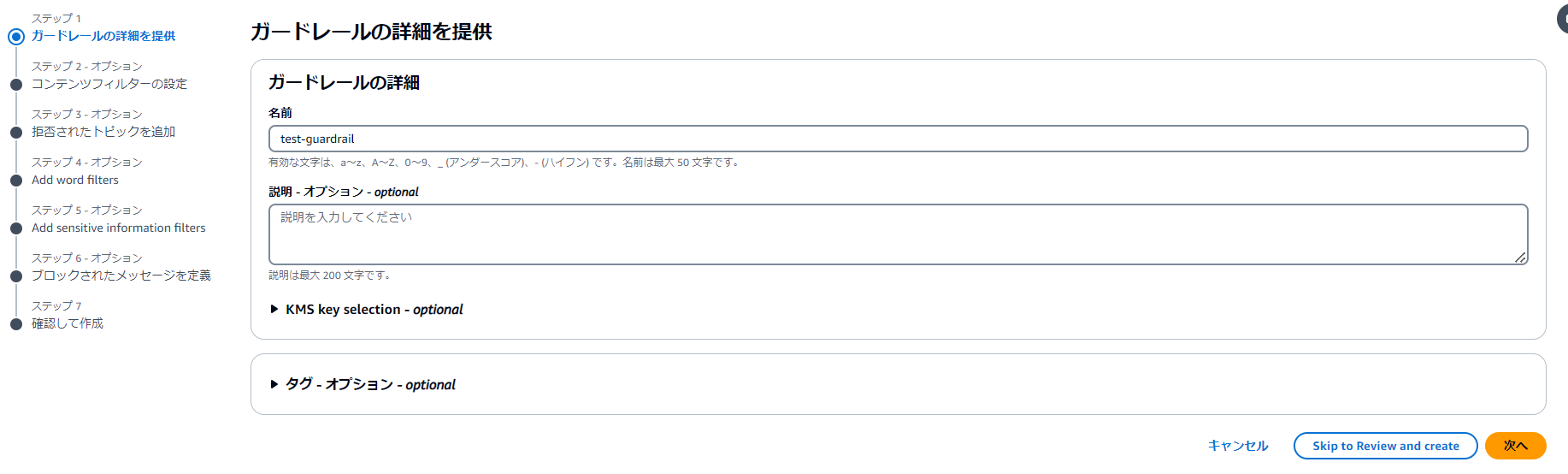
(3)ガードレール名を入力して設定を行います。
(4) 「ユーザーからの入力」(ユーザープロンプト) および「モデルの応答」に対して、コンテンツフィルターを設定します。各項目で強度の設定を行うことができます。

(5)拒否トピックはアプリケーション開発、提供する側で提供を行いたいくないトピックの設定をすることができます。

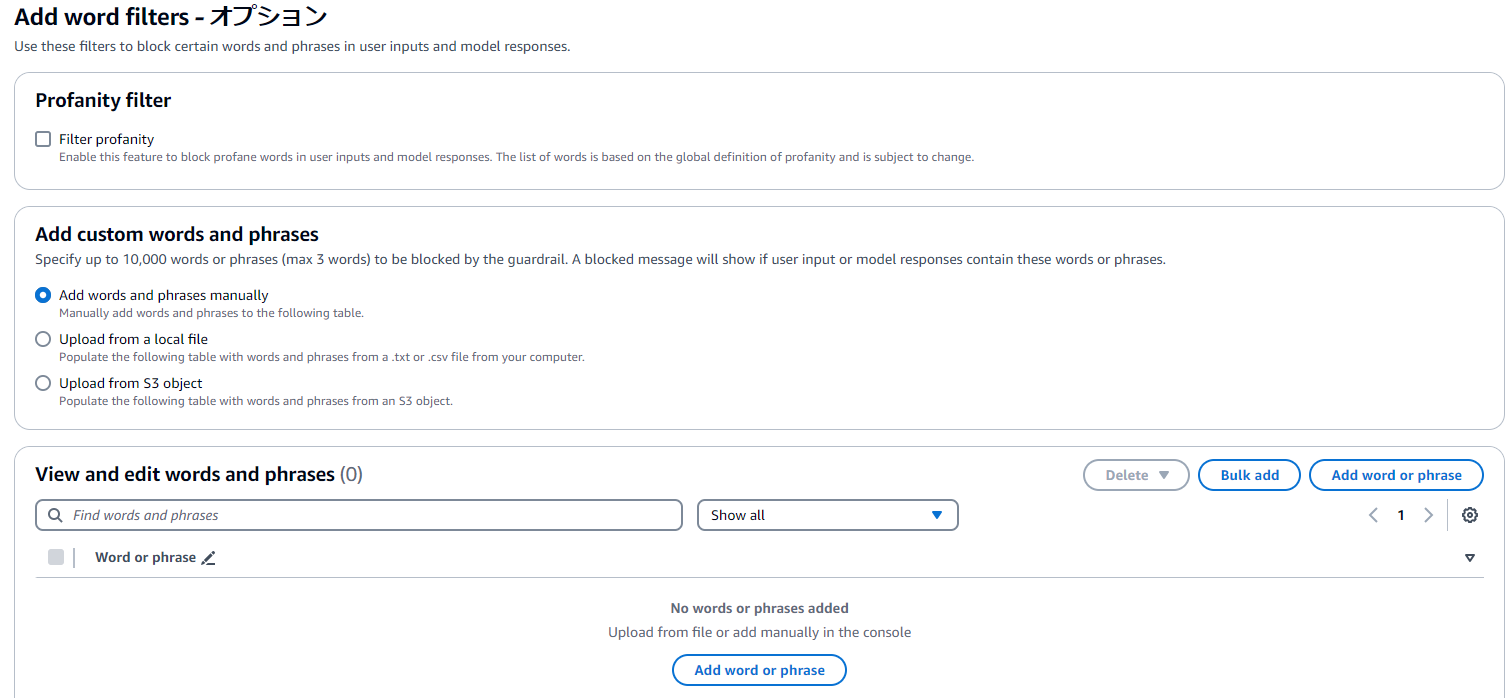
(6)最後にWord Filder機能により、特定の単語を設定することができます。
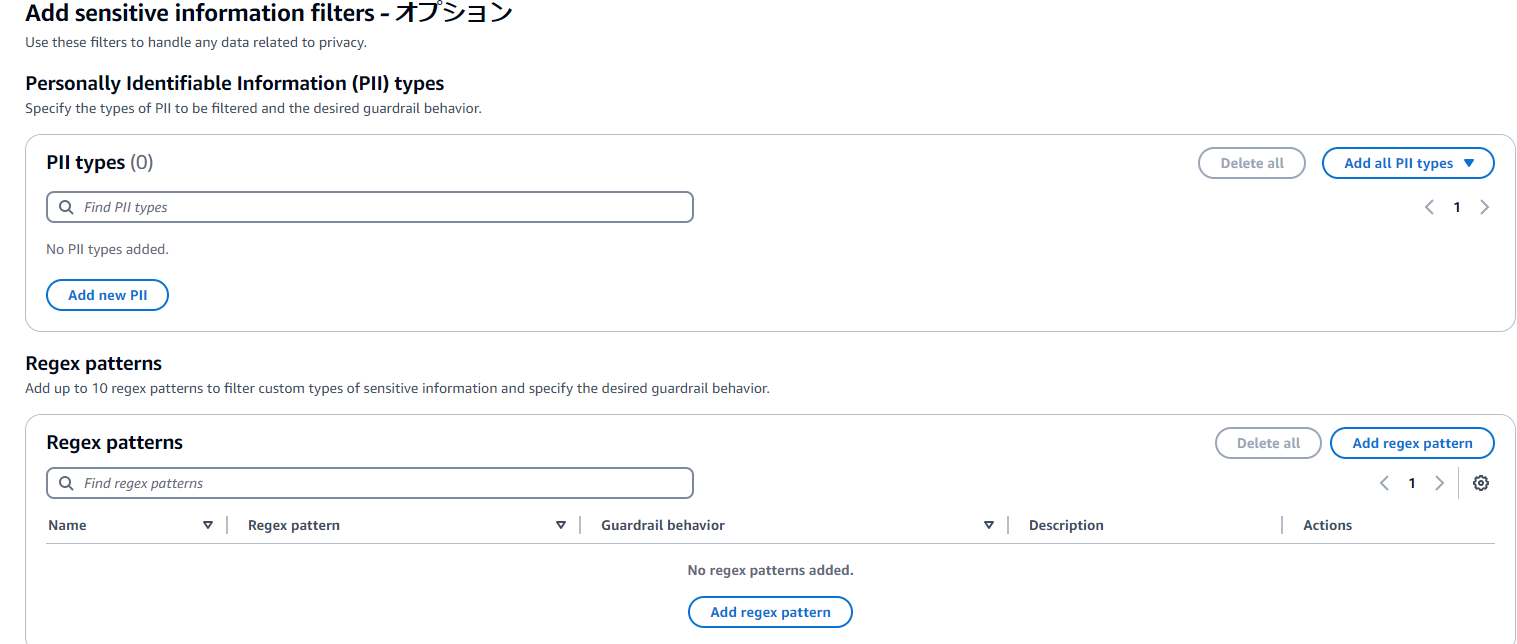
(7) 機微情報 (機密情報や個人情報)についてブロックもしくはマスキングをすることができます。
(8)ガードレール側でブロックした際に出力するメッセージの定義も行うことができます。
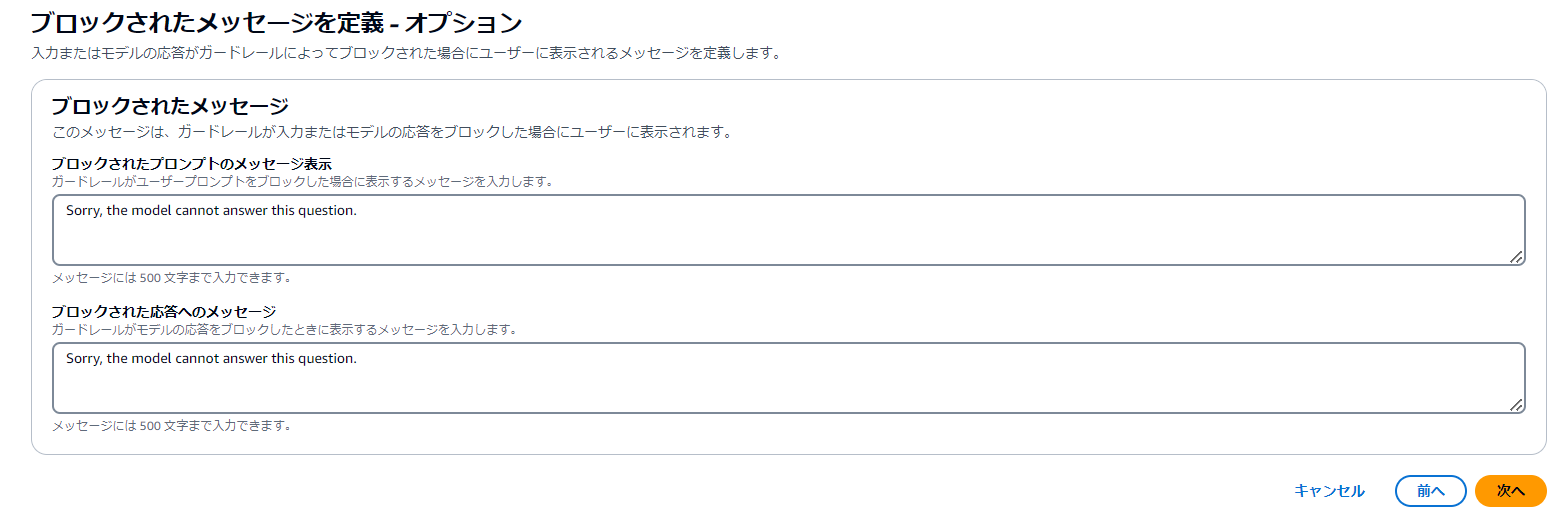
ガードレール作成後に設定したワードが応答しないことを確認してみましょう。強度も色々ありますが、インプット情報に対してどのような制限がかかるのかは色々なデータで検証しがいがあるな、と思いました。
Guardrails for Amazon Bedrock を利用することで、ガイドラインや指針に沿って安全性とプライバシー管理を標準化するメリットがありそうですね。





